2021. 6. 27. 16:26ㆍR 공부/비지도학습
Clustering(군집화)
- 유사한 성질을 가지는 데이터 끼리 cluster(군집)를 나누는 과정
- 목표: 군집 내 데이터들의 거리는 가깝게, 군집간 거리는 멀게

K-means Clustering
- K개의 중심 정하고, 그 중심을 기반으로 clustering 하는 기법이다.
K-means process
- 랜덤하게 K개의 점을 찍고 각 점을 중심으로 데이터들을 할당
- 할당된 군집에서 다시 중심점을 찾고 해당 중심점에서 가장 가까운 데이터로 재 군집화
- 군집에 할당된 데이터들이 바뀌지 않을 때 까지 2번의 과정을 반복

데이터간 거리를 측정하는 방법에는 여러가지 방법이 있다.
많이 사용하는 방법은 유클리드거리, 맨하튼 거리 가 있다.

K-mean clustering 의 활용
군집화 및 군집별 특성 파악
- Ex1) 고객 유형을 분류하여 상품 판매 전략 도출
- Ex2) 제품의 성분 및 특성에 따라 분류하여 제품 추천 로직(알고리즘) 개발
이미지 데이터의 색상을 군집화 하여 사진 색상 축소

그럼 K의 개수를 어떻게 정하냐?
- 사전 정보를 바탕으로 K 개수 설정
-Ex) 꽃의 데이터인데 3종류의 꽃이 있음
- Elbow method
-Within Sum of square(WSS) 그래프에서 Elbow point로 k 개수 설정
- Silhoutte method
- 군집 내 거리(a) 와 최근접 군집 간의 거리(b)를 비교하여 a는 최소, b는 최대가 되는 k 로 개수설정


Sum of square은 중심점에서 퍼져있는 정도를 나타내는 지표이다.

K-modoids clustering
- Medoids = 중앙점
- 군집의 평균점을 찾는 것이 아닌, 중앙점을 찾아 군집화
- 극단치의 영향을 덜 받는 clustering 기법
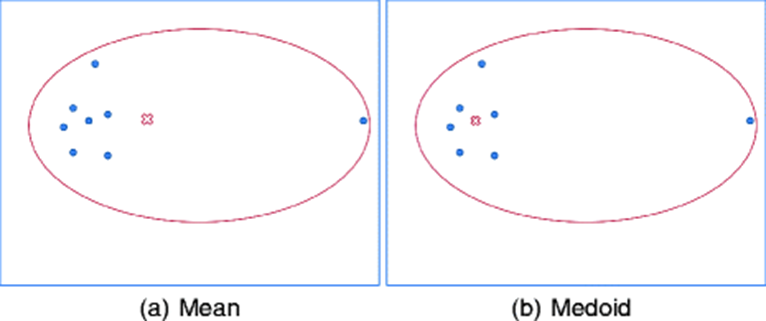


이제 실습을 한번해보자
오늘의 데이터는

customer dataset 이다.
df <- read.csv(file = 'Wholesale customers data.csv',stringsAsFactors = F,header = T)
library(dplyr)
head(df)
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
1 2 3 12669 9656 7561 214 2674 1338
2 2 3 7057 9810 9568 1762 3293 1776
3 2 3 6353 8808 7684 2405 3516 7844
4 1 3 13265 1196 4221 6404 507 1788
5 2 3 22615 5410 7198 3915 1777 5185
6 2 3 9413 8259 5126 666 1795 1451데이터를 불러와서 확인 해본다.
df$Channel <- df$Channel %>% as.factor() #채널 1번 ,2,번 과같이 범주형
df$Region <- df$Region %>% as.factor() # Region도 범주형으로변수들중 필요한건 범주형으로 바꿔준다.
colSums(is.na(df))
Channel Region Fresh Milk Grocery Frozen Detergents_Paper
0 0 0 0 0 0 0
Delicassen
0 각 칼럼별로 결측치가 있는지 확인해준다.
summary(df)
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
1:298 1: 77 Min. : 3 Min. : 55 Min. : 3 Min. : 25.0 Min. : 3.0 Min. : 3.0
2:142 2: 47 1st Qu.: 3128 1st Qu.: 1533 1st Qu.: 2153 1st Qu.: 742.2 1st Qu.: 256.8 1st Qu.: 408.2
3:316 Median : 8504 Median : 3627 Median : 4756 Median : 1526.0 Median : 816.5 Median : 965.5
Mean : 12000 Mean : 5796 Mean : 7951 Mean : 3071.9 Mean : 2881.5 Mean : 1524.9
3rd Qu.: 16934 3rd Qu.: 7190 3rd Qu.:10656 3rd Qu.: 3554.2 3rd Qu.: 3922.0 3rd Qu.: 1820.2
Max. :112151 Max. :73498 Max. :92780 Max. :60869.0 Max. :40827.0 Max. :47943.0각 변수별 기술통계 및 분포를 확인한다.
boxplot(df[,3:ncol(df)]) #channel 과 region 을 빼고 3부터 마지막열까지 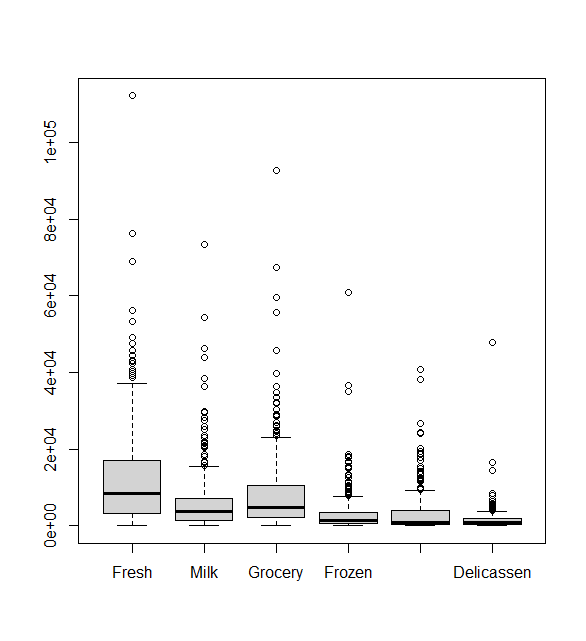
outlier가 많으므로 좀 제거해주고 가야한다. 하지만 세로열의 숫자가 보기 불편하면
options(scipen = 100) 을 입력해주면 된다.

그러면 이런식으로 나온다.
outlier을 제거해주려면
temp <- NULL
for (i in 3:ncol(df)) {
temp <- rbind(temp,df[order(df[,i],decreasing = T),]) %>% slice(1:5)# 변수의 행을 내림차순을 해서 slice 함수를 써서 1행부터 5행까지 자른다.
}
temp <- distinct(temp)
df.rm.outlier <-anti_join(df,temp) #df에서 temp와 같은값 제거
temp에 변수별로 내림차순을 해서 1행부터 5행까지 5개의 값을 넣고
temp의 중복값을 없앤뒤
본래 데이터 df와 temp의 같은 값을 제거하면된다.
그렇게 해서 outlier을 제거해주면
par(mfrow= c(1,2)) #한 화면에 여러그림을 넣기위함(1행 2열로 배치시켜라)
boxplot(df[,3:ncol(df)])
boxplot(df.rm.outlier[,3:ncol(df)])
왼쪽이 원래이고 오른쪽이 outlier을 제거한것인데 조금은 없어진거같지만 별 변화가 없는거 같다;;
그럼 이제 K-means를 직접 실행해보자
일단 Elbow method를 통해서 K 군집 개수를 설정한다.
install.packages("factoextra")
library(factoextra)
set.seed(2020) #난수 고정
#k 군집 개수 설정(Elbow method)
fviz_nbclust(df.rm.outlier[,3:ncol(df.rm.outlier)],kmeans,method = "wss",k.max = 15)+ #wss =withis sum of square, 15개까지 군집그래프를 그려줘라
theme_minimal()+ggtitle("Elbow Method") #그래프 테마, 그래프 제목
꺾이는 부분이 4인지 9인지 헷갈린다.....;;
다음은 Silhouette method를 통해 구해본다
#k 군집 개수 설정(Silhouette method)
fviz_nbclust(df.rm.outlier[,3:ncol(df.rm.outlier)],kmeans,method = "silhouette",k.max = 15)+
theme_minimal()+ ggtitle("Silhouette plot")
여기선 k가 2라고 나온다.
k를 무엇으로 해야 할까.. 근데 고객의 구매데이터니깐 2개는 너무작고 9개는 너무많고 4개가 적당한거같다.
k를 4개로 설정한다.
k-means 모델을 생성해보자
df.kmeans <- kmeans(df.rm.outlier[,3:ncol(df.rm.outlier)],center = 4, iter.max = 1000) #center에 k값을 넣어줌
df.kmeans
K-means clustering with 4 clusters of sizes 142, 51, 196, 46
Cluster means:
Fresh Milk Grocery Frozen Detergents_Paper Delicassen #각 클러스터의 평균값
1 14555.725 2787.944 3965.261 3647.204 962.7183 1202.535
2 33215.804 6036.863 6236.098 6390.275 1019.6078 3047.176
3 3842.128 4615.107 6513.653 1796.847 2519.0918 1106.173
4 8621.174 19552.152 28258.543 2114.391 12565.0000 2388.174
Clustering vector: #각각의 데이터들의 몇번 군집에 들어갔는가
[1] 1 3 3 1 1 3 1 3 3 4 3 1 2 1 2 1 3 3 1 3 1 3 2 4 2 1 1 1 4 2 1 3 1 2 3 3 2 1 4 2 1 3 4 3 4 4 4 3 4 3 3 2 3 2
[55] 3 4 3 1 3 3 4 3 3 3 4 3 1 3 1 1 1 3 1 3 1 3 4 1 3 3 3 3 1 1 4 4 2 1 2 1 1 4 1 3 3 3 3 3 1 3 3 3 2 1 1 3 3 3
[109] 4 1 4 1 1 1 1 1 3 1 1 1 3 1 3 2 1 1 3 2 1 3 1 1 3 3 3 3 1 3 1 2 2 1 1 4 3 1 3 2 1 3 1 3 3 4 3 1 3 3 3 1 1 4
[163] 3 4 3 3 3 3 3 4 3 3 3 3 2 1 1 3 1 3 2 3 3 3 3 3 3 1 1 3 3 3 1 2 3 1 1 4 4 2 3 3 4 3 3 3 4 1 4 3 3 3 3 4 1 3
[217] 3 1 3 3 3 3 1 1 3 3 1 1 3 2 3 1 3 1 1 3 2 1 1 1 1 3 3 1 1 1 1 3 4 3 2 3 2 1 1 2 1 1 1 3 3 4 4 1 4 1 3 3 3 2
[271] 3 3 2 1 1 1 3 1 2 2 2 3 1 1 2 3 3 3 3 1 3 1 3 3 3 1 4 3 3 4 3 4 1 3 4 1 2 3 1 1 3 3 3 1 4 3 1 1 1 2 2 3 3 1
[325] 3 1 4 1 4 1 2 1 1 3 3 3 3 3 4 3 3 3 2 3 4 3 4 3 3 1 3 1 3 3 3 1 3 3 3 3 3 1 3 1 3 2 1 3 1 3 3 3 2 3 3 2 1 2
[379] 3 4 1 3 1 1 1 3 3 3 2 1 1 3 1 1 1 3 2 2 2 1 3 2 4 3 3 3 3 3 3 3 3 3 3 3 1 3 1 2 1 1 1 1 2 3 3 3 1 1 3 1 2 2
[433] 4 1 3
Within cluster sum of squares by cluster:
[1] 8048287798 14121987584 11915827433 25153538478
(between_SS / total_SS = 56.0 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size"
[8] "iter" "ifault"
barplot(t(df.kmeans$centers),beside = TRUE,col = 1:6) # center의 값을 bar로 표현
legend("topleft",colnames(df[,3:8]),fill = 1:6,cex = 0.5)#범례
4개의 군집으로 각각 무엇을 구매했는지 알수있다.
df.rm.outlier$cluster <- df.kmeans$cluster
head(df.rm.outlier)
#데이터 별로 군집표시를 해줌
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen cluster
1 2 3 12669 9656 7561 214 2674 1338 1
2 2 3 7057 9810 9568 1762 3293 1776 3
3 2 3 6353 8808 7684 2405 3516 7844 3
4 1 3 13265 1196 4221 6404 507 1788 1
5 2 3 22615 5410 7198 3915 1777 5185 1
6 2 3 9413 8259 5126 666 1795 1451
이번엔 사진데이터를 k-means 를 통해 해보겠다.
library(jpeg)
img <- readJPEG('cat.jpg')
class(img)
dim(img)
[1] 360 480 3
#3차원 데이터를 2차원으로 펼침
imgdim <- as.vector(dim(img))
imgRGB <- data.frame(
x=rep(1:imgdim[2],each = imgdim[1]), #1부터 480 까지를 반복, 각각을 360번 반복
y=rep(imgdim[1]:1,imgdim[2]), #360에서 1까지를 480번 반복해줘라
R=as.vector(img[,,1]),
G=as.vector(img[,,2]),
B=as.vector(img[,,3])
)
head(imgRGB)
x y R G B
1 1 360 0.1019608 0.2235294 0.1921569
2 1 359 0.1019608 0.2235294 0.2000000
3 1 358 0.1019608 0.2235294 0.2000000
4 1 357 0.1058824 0.2274510 0.1960784
5 1 356 0.1137255 0.2352941 0.2039216
6 1 355 0.1058824 0.2352941 0.2078431
RGB값을 통해서 비슷한거 끼리 군집화해서 색상을 축소한다.
kClusters <- c(3,5,10,15,30,50) #축소할 색상 클러스터 개수
set.seed(2020)
for ( i in kClusters) {
img.kmeans <- kmeans(imgRGB[,c("R","G","B")], centers = i) #군집개수는 3개
img.result <- img.kmeans$centers[img.kmeans$cluster,]
img.array <- array(img.result,dim = imgdim)
writeJPEG(img.array,paste('kmeans_',i,'clusters.jpeg',sep = ' '))
}







'R 공부 > 비지도학습' 카테고리의 다른 글
| Hieararchical Clustering Analysis (0) | 2021.06.28 |
|---|---|
| PCA(주성분 분석) (0) | 2021.06.26 |