2021. 6. 25. 16:54ㆍR 공부/지도학습
Decision Tree는 한국말로는 의사결정나무 라고 불린다.
오늘의 예는 배드민턴을 칠건가? 말건가? 에 대해서 알아보자

일단 트리구조를 보자

자료구조의 tree와 흡사하다.

부모노드 와 자식노드로 이루어져 있다.

결과로는 결과와 다른 테스트가 나오는 경우가 있다.
그럼 밑으로 계속 테스트가 이어진다.
그럼 좋은 테스트란?

가능한 한 가장 작은 나무가 나오는 것이 좋은 테스트이다.
먼저 날씨 테스트를 해보자

흐림이나 비는 잘 구분되어있다. 하지만 맑을때는 네 2개 아니오 2개이므로 다른 테스트를 해야한다.
잘 구분된 데이터는 흐림 3개 비 1개이므로 4점이다.
그다음은 바람테스트이다.
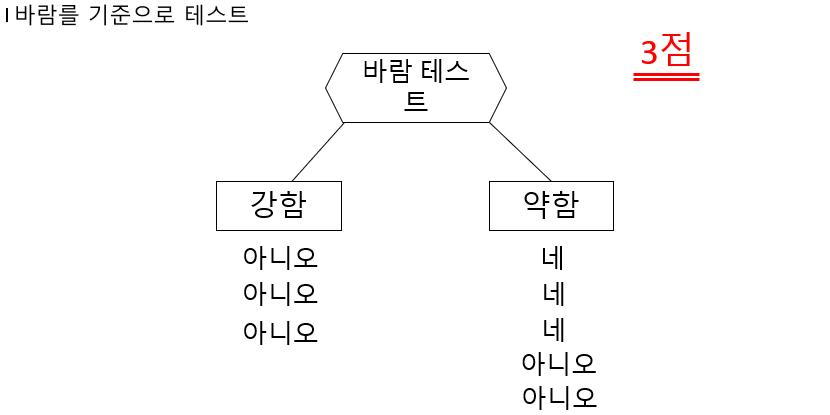
여기는 강함이 3개가 잘 구분되어있으므로 3점이다.
이와 같이 온도와 습도 테스트 까지 완료해준다.

decision tree는 가장 성능 좋은 tree를 위로 올린다.
그러면 날씨 테스트가 올라간다.
날씨 테스트는 맑음 컬럼에 네 , 아니오가 섞여있으므로
두번째 테스트가 필요하다.
두번째 테스트는 날씨가 맑음 인 데이터 4개만 본다.
4개의 데이터로 바람,온도,습도 테스트를 한다.

두번째 테스트로 바람이 선정된다.

그럼 최종적으로 decision tree 가 완성 된다.

Decision Tree에서 각 트리의 스코어링 방법
노트별 무질서 측정 후 퀄리티 테스트한다.

↓

실제로 무질서 점수를 구해보자


T = (전체데이터개수) 4
P = (긍정,예) 2
N = (부정,아니오) 2
무질서 값은 1이된다.
이런식으로 흐림, 비도 해주면 둘다 무질서 값은 0 이 나온다.
그다음 퀄리티 테스트를 한다.



테스트 점수는 낮을수록 좋다.
피쳐가 범주형이아닌 연속형인 경우 어떻게 할것인가?

기준을 나눠서 범주형으로 바꿔준다.
위의 예에서 보면 25를 기준으로 나눴을때 가장 잘 분류된다.
그럼 피쳐가 아닌 타켓이 범주형인경우는?
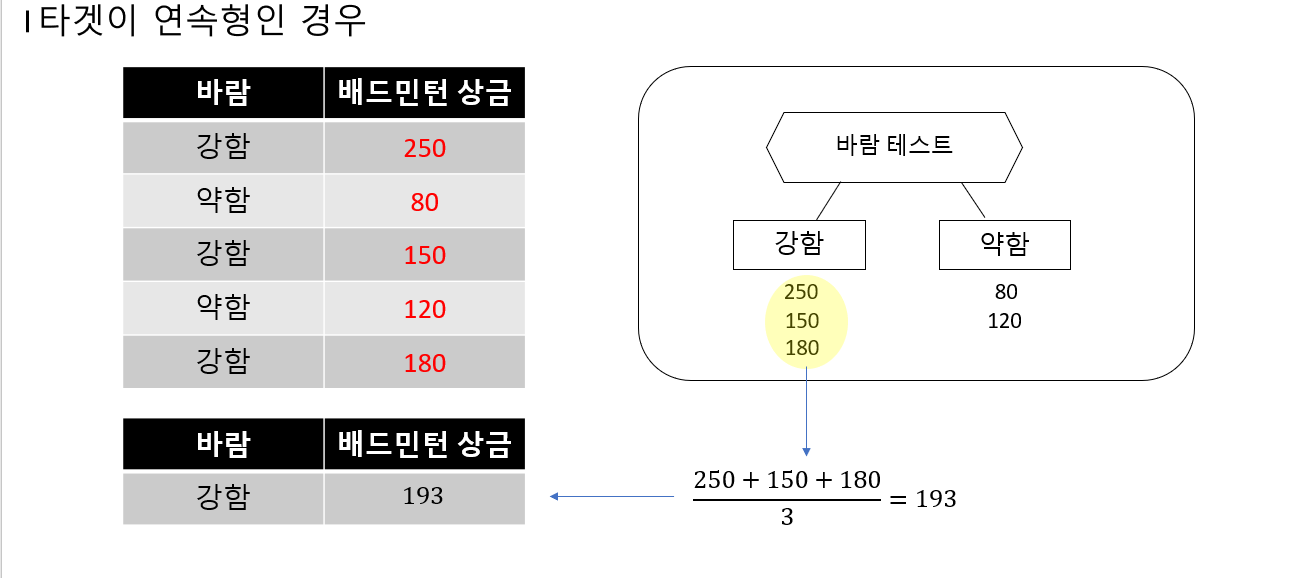
값을 분류한후 각 노드의 값들의 평균을 구한후 예측값으로 사용한다.
Decision Tree 의 단점이 무엇일까?
오버피팅이 일어날수있다.
단점을 보완하기 위해 나온 방법이 Random Forest이다.
Random Forest 는 Decision Tree를 여러개 모아서 수행하는것이다.
Radom Forest 의 순서는
- n개의 랜덤 데이터 샘플 선택( 중복 가능)
- d개의 피쳐 선택(중복 불가능)
- Decision Tree 학습
- 각 Decision Tree 결과의 투표를 통해 클래스 할당

트레이닝 데이터에서 중복을 허용하여 랜덤 샘플링 하는것을 배깅(bagging)이라고 한다.
bagging 은 bootstrap aggregating 의 약자이다.


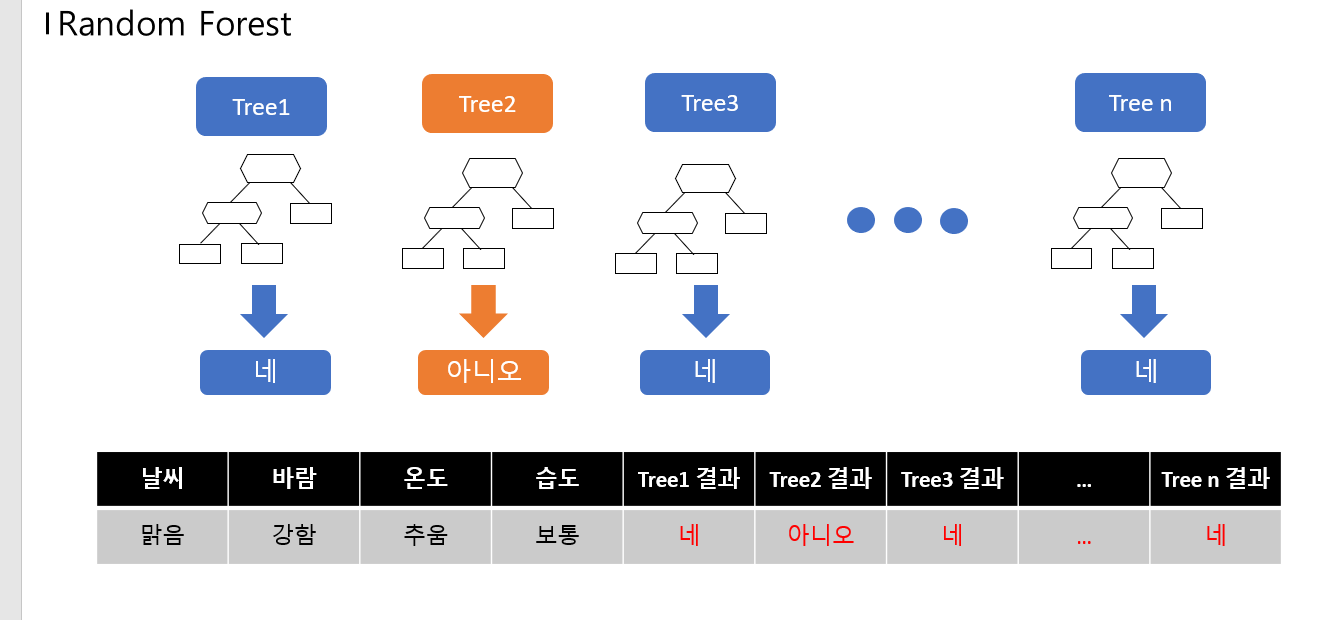

Decision 트리와 Random Forest를 하는 과정

한번 실습해보자
library(caret)
rawdata <- read.csv(file = "wine.csv",header = TRUE)
rawdata$Class <- as.factor(rawdata$Class)
str(rawdata)
패키지를 사용하고
wine데이터를 불러오며 Class 변수는 범주형으로 만들어준다.
Class 변수는 타겟인데 타겟은 구분하기를 원하는것이다.
와인에서는 와인종류가 1,2,3이 있는데 1인지2인지3인지를 구분하도록해주는 변수이다.
analdata <- rawdata
set.seed(2020)
datatotal <- sort(sample(nrow(analdata),nrow(analdata)*.7))
train <- rawdata[datatotal,]
test <- rawdata[-datatotal,]
train_x <- train[,1:13]
train_y <- train[,14]
test_x <- test[,1:13]
test_y <- test[,14]데이터를 train 데이터와 test 데이터로 나눈다.
그리고 피쳐부분과 타겟부분으로 나누는것이다.
피쳐부분이: train_x,test_y
타켓부분이: train_y,test_y
install.packages("tree")
library(tree)
패키지를 설치하고
treeRaw <- tree(Class~.,data = train) #tree(타겟~피쳐(.이면all임) , 데이터)
plot(treeRaw)
text(treeRaw)
기본적인 트리를 만들어준다.

cv_tree <- cv.tree(treeRaw,FUN = prune.misclass) #cv.tree(기본적인트리,FUN(함수)= prune.missclass(오분류)
plot(cv_tree)
Decision Tree의 최적 사이즈는 4가 된다.
misclass가 낮을수록 좋다 오분류 확률이 낮아지므로!
오분류가 제일 작은것중에 사이즈가 제일 작은걸 선택한다.
Tree size

prune_tree <- prune.misclass(treeRaw,best = 4)
plot(prune_tree)
text(prune_tree,pretty = 0)가지치기를 해준다.

가지치기를 한후 굉장히 깔끔해졌다.
pred <- predict(prune_tree,test,type = 'class')
confusionMatrix(pred,test$Class)
만들어진 tree모형을 이용해서 test데이터를 예측해보면
Confusion Matrix and Statistics
Reference
Prediction 1 2 3
1 14 2 4
2 0 23 0
3 0 2 9
Overall Statistics
Accuracy : 0.8519
95% CI : (0.7288, 0.9338)
No Information Rate : 0.5
P-Value [Acc > NIR] : 6.922e-08
Kappa : 0.7692
Mcnemar's Test P-Value : 0.04601
Statistics by Class:
Class: 1 Class: 2 Class: 3
Sensitivity 1.0000 0.8519 0.6923
Specificity 0.8500 1.0000 0.9512
Pos Pred Value 0.7000 1.0000 0.8182
Neg Pred Value 1.0000 0.8710 0.9070
Prevalence 0.2593 0.5000 0.2407
Detection Rate 0.2593 0.4259 0.1667
Detection Prevalence 0.3704 0.4259 0.2037
Balanced Accuracy 0.9250 0.9259 0.8218정확도가 85%인것을 알수있다. Decision Tree는 오버피팅이 있을수 있기때문에 정확도가 낮게나온다.
이럴때 Random Forest 를 사용한다.
library(caret)
ctrl <- trainControl(method = "repeatedcv",repeats = 5) #학습 파라미터 설정
rfFit <- train(Class~.,
data = train,
method = "rf",
trControl = ctrl,
preProcess = c("center","scale"),
metric = "Accuracy"
)
rfFit결과는
Random Forest
124 samples
13 predictor
3 classes: '1', '2', '3'
Pre-processing: centered (13), scaled (13)
Resampling: Cross-Validated (10 fold, repeated 5 times)
Summary of sample sizes: 111, 110, 111, 112, 112, 111, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9904529 0.9855947
7 0.9807326 0.9708665
13 0.9594539 0.9385166
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 2.
mtry가 2일때 가장 정확하게 나온다. mtry란 랜덤 피쳐개수 라고할수있다.
랜덤 피쳐개수랑 각 트리별로 피쳐를 몇개 사용하느냐 라는 뜻이다.
pred_test <- predict(rfFit,newdata = test)
confusionMatrix(pred_test,test$Class)만들어진 모델로 예측을 해보면
Confusion Matrix and Statistics
Reference
Prediction 1 2 3
1 14 0 0
2 0 26 0
3 0 1 13
Overall Statistics
Accuracy : 0.9815
95% CI : (0.9011, 0.9995)
No Information Rate : 0.5
P-Value [Acc > NIR] : 3.053e-15
Kappa : 0.9706
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: 1 Class: 2 Class: 3
Sensitivity 1.0000 0.9630 1.0000
Specificity 1.0000 1.0000 0.9756
Pos Pred Value 1.0000 1.0000 0.9286
Neg Pred Value 1.0000 0.9643 1.0000
Prevalence 0.2593 0.5000 0.2407
Detection Rate 0.2593 0.4815 0.2407
Detection Prevalence 0.2593 0.4815 0.2593
Balanced Accuracy 1.0000 0.9815 0.9878정확도가 98.15%가 나온다. 아주 정확하다.
변수중요도도 체크해보자
importance_rf <- varImp(rfFit,scale = FALSE)
plot(importance_rf)
proline 변수가 가장 중요하게 적용되는걸 볼수있다.
Decision Tree 와 Random Forest 정확도는 85.19% vs 98.15% 가 나온다.
'R 공부 > 지도학습' 카테고리의 다른 글
| Naive Bayes Classification (0) | 2021.06.24 |
|---|---|
| Logistic Regression (0) | 2021.06.24 |
| KNN(K-Nearest Neighbor) (2) | 2021.06.23 |